Python网络爬虫实战之十四:Scrapy结合scrapy-splash爬取动态网页数据
少儿编程 7年前 (2019-05-21) 3733浏览 0评论
一、Scrapy爬取动态网页数据的原理 之前我们学习的内容都是抓取静态页面,每次请求,它的网页全部信息将会一次呈现出来。 但是,像比如一些购物网站...
少儿编程 7年前 (2019-05-21) 3733浏览 0评论
一、Scrapy爬取动态网页数据的原理 之前我们学习的内容都是抓取静态页面,每次请求,它的网页全部信息将会一次呈现出来。 但是,像比如一些购物网站...
少儿编程 7年前 (2019-05-21) 2967浏览 0评论
本文爬取的是这个网站:hhttp://comic.kukudm.com/comiclist/5/ 一、创建项目 在开始爬取之前,我们必须创建一个...
少儿编程 7年前 (2019-05-21) 2547浏览 0评论
案例一:爬取微博天气 网页链接:http://weather.sina.com.cn 创建项目 scrapy startproject w...
少儿编程 7年前 (2019-05-21) 2576浏览 0评论
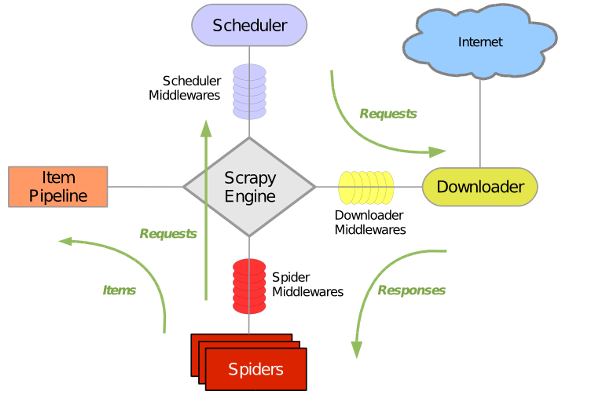
一、Scrapy简介 Scrapy是一个高级的Python爬虫框架,它不仅包含了爬虫的特性,还可以方便的将爬虫数据保存到csv、json等文件中。...
少儿编程 7年前 (2019-05-21) 2636浏览 0评论
一、什么是API? API(ApplicationProgrammingInterface,应用程序编程接口)是一些预先定义的函数,目的是提供应用...
少儿编程 7年前 (2019-05-21) 2662浏览 0评论
一、Selenium进阶操作 1、回顾 Selenium 打开有界面的浏览器 from selenium import webdriver f...
少儿编程 7年前 (2019-05-21) 2563浏览 0评论
一、Headless Chrome 1、什么是 Headless Chrome Headless Chrome 是 Chrome 浏览器的无界面...
少儿编程 7年前 (2019-05-21) 2243浏览 0评论
一、Selenium 1、Selenium是什么 Selenium 是什么?一句话,自动化测试工具。它支持各种浏览器,包括 Chrome,Safar...

少儿编程 7年前 (2019-05-21) 2733浏览 0评论
预备知识点:正则表达式之 pattern+?、pattern*?、(?!pattern)、(?:pattern) pattern+?、pattern*...

少儿编程 7年前 (2019-05-21) 2383浏览 0评论
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者...
少儿编程 7年前 (2019-05-21) 2053浏览 0评论
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方...
少儿编程 7年前 (2019-05-21) 2489浏览 0评论
一、urllib urllib简介 urllib是Python中一个功能强大用于操作URL,并在爬虫时经常用到的一个基础库,无需额外安装,默认已...

少儿编程 7年前 (2019-05-21) 2153浏览 0评论
一、Python的环境部署 Python安装、Python的IDE安装本文不再赘述,网上有很多教程 爬虫必备的几个库:Requests、Sele...
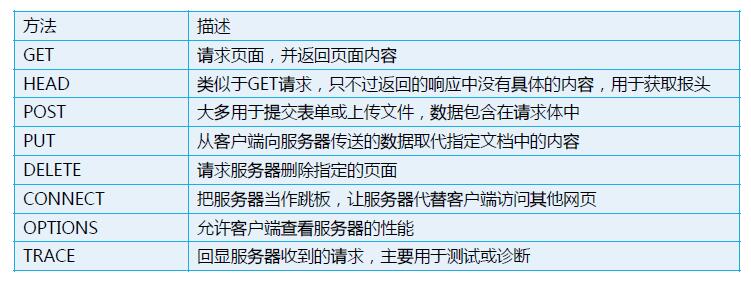
少儿编程 7年前 (2019-05-21) 2234浏览 0评论
一、浏览网页的基本过程和通信基础 当我们在浏览器地址栏输入: http://www.kidscoding8.com 回车后会浏览器显示百度的首页,那这...