码丁实验室,一站式儿童编程学习产品,寻地方代理合作共赢,微信联系:leon121393608。
插入排序:
时间复杂度O(n^2)
代码很短,解释一下,l是要排序的部分的最左一位,r是最右一位,为了方便理解,这里l=1,r=10。
插入排序的主要思想是每次往已经有序的序列中插入一个数,这里可以把i左边的看成已经有序的,i右边的看为正在排序的序列,第i位即是当前所需插入的数。
我们逐句分析:i设定为1+1,也就是第二位,重复执行直到i>10。
这里可以看成for(int i=1+1;i<=10;i++)也就是从第2位扫到第10位。
然后j设定为1,重复执行知道j>i-1也就是从第1位扫到第i-1位,直到找到一个比当前需要插入的数还要大的数,将数插入。
假设有一个序列{1,3,5,2,8,4,9,6,10,7}
我们来模拟一下原程序。
{1,3,5,2,8,4,9,6,10,7}
——i—————————————-
{1,3,5,2,8,4,9,6,10,7}
———–i———————————–
{1,3,5,2,8,4,9,6,10,7}
—————-i——————————
{1,2,3,5,8,4,9,6,10,7}
——————–i————————–
{1,2,3,5,8,4,9,6,10,7}
————————-i———————
{1,2,3,4,5,8,9,6,10,7}
——————————i—————-
{1,2,3,4,5,8,9,6,10,7}
———————————-i————
{1,2,3,4,5,6,8,9,10,7}
—————————————-i——
{1,2,3,4,5,6,8,9,10,7}
———————————————i-
{1,2,3,4,5,6,7,8,9,10}
———————————————–i 这时i>10跳出循环。
插入排序是一种很容易理解的排序,但是速度较慢。
冒泡排序:
时间复杂度O(n^2)
 代码也很短。
代码也很短。冒泡排序的思想是重复走这个序列,每次比较两个相邻的元素,如果发现他们不符合顺序便交换两者。这个很好理解。就不过多解释了,另外提一下,如果比较的时候用的是>或<小于,冒泡就是稳定的,但如果用的是≥或≤,冒泡便变成了不稳定的算法。
选择排序:
顾名思义,每次找到未排序部分最小的数,放到已排序序列的末尾。
本来有个模拟的。。。不小心刷新网页了![]() 不想再写一遍
不想再写一遍
其实很好理解的啦,仔细看看
归并排序(开始比较精彩的了):
 程序:
程序: 归并排序是一个采用分治法的一个非常经典的运用,没错,用到了递归
归并排序是一个采用分治法的一个非常经典的运用,没错,用到了递归我们来看一张图:
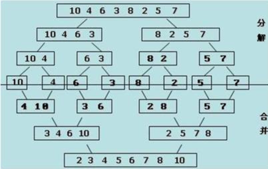
这个程序先将这个序列拆分成很多个小序列(程序上面一部分),拆分到无法拆分时便开始合并。
合并过程很简单(程序下面一部分),其实就是二路归并,这里贴个链接,讲的很详细:https://www.cnblogs.com/chengxiao/p/6194356.html)
因为每一边的序列都是有序的,所以可以用这种二路归并的方式。
归并排序的缺点就是空间占用大,我们需要另一个数组来储存归并后的序列,然后再复制到原数组。
快速排序(喜闻乐见):
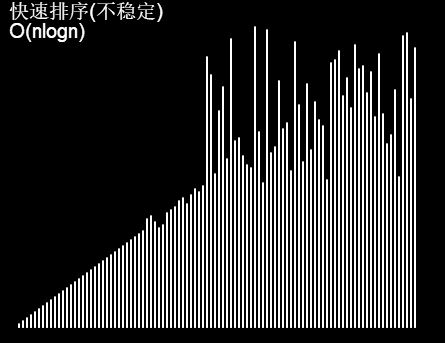
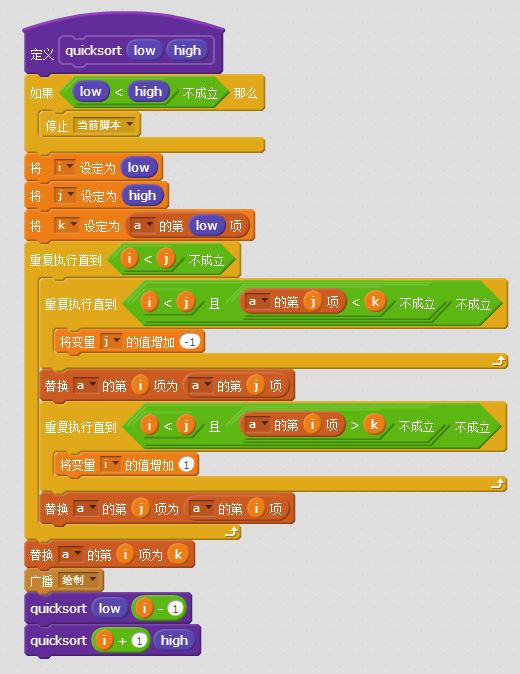
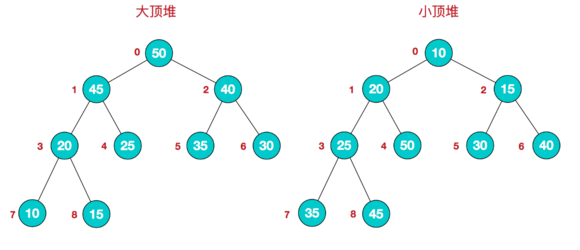
堆排序:
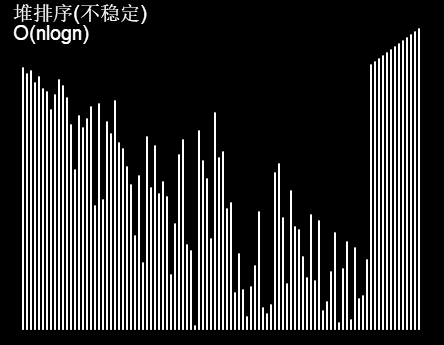 堆排序对于新手来说可能会很懵逼(我不就是新手吗),所以程序放后面。
堆排序对于新手来说可能会很懵逼(我不就是新手吗),所以程序放后面。